AUS2200 xarray rolling mean¶
Aim¶
This recipe shows how to: - Load a month of AUS2200 data (entire spatial domain) with xarray (dask-enabled) and chunk the data for efficient computing - Calculate air temperature perturbations to the daily mean (using xarray rolling mean)
First load some python modules¶
Requires access to the hh5 conda environment
[1]:
import pandas as pd
import xarray as xr
import datetime as dt
import numpy as np
import matplotlib.pyplot as plt
import cartopy.crs as ccrs
import dask.array as da
import dask
from dask.distributed import Client
from dask import delayed
Dask-optimiser¶
Note that we loaded dask-optimiser into our ARE session. You can load this by modifying your ARE setup under “modules” (conda/analysis3 dask-optimiser). This module ensures that dask is optimally set up for working on Gadi
Compute size¶
We are working with XX-Large resources on ARE (28 cores, 126 GB)
[2]:
#Set up a dask distributed client, so that chunks of data can be sent and
# processed by different cores/"workers".
# Click "Launch dashboard in JupyterLab" within this cell's output to see dask progress
client = Client()
client
2024-12-05 21:15:01,259 - distributed.preloading - INFO - Creating preload: /g/data/hh5/public/apps/dask-optimiser/schedplugin.py
2024-12-05 21:15:01,264 - distributed.utils - INFO - Reload module schedplugin from .py file
2024-12-05 21:15:01,290 - distributed.preloading - INFO - Import preload module: /g/data/hh5/public/apps/dask-optimiser/schedplugin.py
Modifying workers
[2]:
Client
Client-c9b2f7d6-b2f1-11ef-b9d5-000007a3fe80
| Connection method: Cluster object | Cluster type: distributed.LocalCluster |
| Dashboard: /node/gadi-hmem-bdw-0003.gadi.nci.org.au/26997/proxy/8787/status |
Cluster Info
LocalCluster
cfe7d788
| Dashboard: /node/gadi-hmem-bdw-0003.gadi.nci.org.au/26997/proxy/8787/status | Workers: 21 |
| Total threads: 21 | Total memory: 0 B |
| Status: running | Using processes: True |
Scheduler Info
Scheduler
Scheduler-4fabb379-b10c-4566-8924-37984f9007d2
| Comm: tcp://127.0.0.1:42321 | Workers: 21 |
| Dashboard: /node/gadi-hmem-bdw-0003.gadi.nci.org.au/26997/proxy/8787/status | Total threads: 21 |
| Started: Just now | Total memory: 0 B |
Workers
Worker: 0
| Comm: tcp://127.0.0.1:42101 | Total threads: 1 |
| Dashboard: /node/gadi-hmem-bdw-0003.gadi.nci.org.au/26997/proxy/44945/status | Memory: 0 B |
| Nanny: tcp://127.0.0.1:46475 | |
| Local directory: /jobfs/130201066.gadi-pbs/dask-scratch-space/worker-rcjfhbyz | |
Worker: 1
| Comm: tcp://127.0.0.1:40749 | Total threads: 1 |
| Dashboard: /node/gadi-hmem-bdw-0003.gadi.nci.org.au/26997/proxy/41077/status | Memory: 0 B |
| Nanny: tcp://127.0.0.1:45355 | |
| Local directory: /jobfs/130201066.gadi-pbs/dask-scratch-space/worker-du2ws66i | |
Worker: 2
| Comm: tcp://127.0.0.1:41883 | Total threads: 1 |
| Dashboard: /node/gadi-hmem-bdw-0003.gadi.nci.org.au/26997/proxy/34133/status | Memory: 0 B |
| Nanny: tcp://127.0.0.1:38809 | |
| Local directory: /jobfs/130201066.gadi-pbs/dask-scratch-space/worker-41b3yrg8 | |
Worker: 3
| Comm: tcp://127.0.0.1:42099 | Total threads: 1 |
| Dashboard: /node/gadi-hmem-bdw-0003.gadi.nci.org.au/26997/proxy/45357/status | Memory: 0 B |
| Nanny: tcp://127.0.0.1:37929 | |
| Local directory: /jobfs/130201066.gadi-pbs/dask-scratch-space/worker-72s9lchp | |
Worker: 4
| Comm: tcp://127.0.0.1:38463 | Total threads: 1 |
| Dashboard: /node/gadi-hmem-bdw-0003.gadi.nci.org.au/26997/proxy/38583/status | Memory: 0 B |
| Nanny: tcp://127.0.0.1:34845 | |
| Local directory: /jobfs/130201066.gadi-pbs/dask-scratch-space/worker-631uf7mx | |
Worker: 5
| Comm: tcp://127.0.0.1:45155 | Total threads: 1 |
| Dashboard: /node/gadi-hmem-bdw-0003.gadi.nci.org.au/26997/proxy/38585/status | Memory: 0 B |
| Nanny: tcp://127.0.0.1:39601 | |
| Local directory: /jobfs/130201066.gadi-pbs/dask-scratch-space/worker-ovkupuxm | |
Worker: 6
| Comm: tcp://127.0.0.1:33681 | Total threads: 1 |
| Dashboard: /node/gadi-hmem-bdw-0003.gadi.nci.org.au/26997/proxy/46659/status | Memory: 0 B |
| Nanny: tcp://127.0.0.1:39301 | |
| Local directory: /jobfs/130201066.gadi-pbs/dask-scratch-space/worker-waq0ru9v | |
Worker: 7
| Comm: tcp://127.0.0.1:34283 | Total threads: 1 |
| Dashboard: /node/gadi-hmem-bdw-0003.gadi.nci.org.au/26997/proxy/40295/status | Memory: 0 B |
| Nanny: tcp://127.0.0.1:41419 | |
| Local directory: /jobfs/130201066.gadi-pbs/dask-scratch-space/worker-zt24rxye | |
Worker: 8
| Comm: tcp://127.0.0.1:33351 | Total threads: 1 |
| Dashboard: /node/gadi-hmem-bdw-0003.gadi.nci.org.au/26997/proxy/46717/status | Memory: 0 B |
| Nanny: tcp://127.0.0.1:34441 | |
| Local directory: /jobfs/130201066.gadi-pbs/dask-scratch-space/worker-sgb2l3s1 | |
Worker: 9
| Comm: tcp://127.0.0.1:43465 | Total threads: 1 |
| Dashboard: /node/gadi-hmem-bdw-0003.gadi.nci.org.au/26997/proxy/35125/status | Memory: 0 B |
| Nanny: tcp://127.0.0.1:43637 | |
| Local directory: /jobfs/130201066.gadi-pbs/dask-scratch-space/worker-m2was2iz | |
Worker: 10
| Comm: tcp://127.0.0.1:45101 | Total threads: 1 |
| Dashboard: /node/gadi-hmem-bdw-0003.gadi.nci.org.au/26997/proxy/43919/status | Memory: 0 B |
| Nanny: tcp://127.0.0.1:46427 | |
| Local directory: /jobfs/130201066.gadi-pbs/dask-scratch-space/worker-pq2u4jhl | |
Worker: 11
| Comm: tcp://127.0.0.1:37251 | Total threads: 1 |
| Dashboard: /node/gadi-hmem-bdw-0003.gadi.nci.org.au/26997/proxy/33599/status | Memory: 0 B |
| Nanny: tcp://127.0.0.1:36067 | |
| Local directory: /jobfs/130201066.gadi-pbs/dask-scratch-space/worker-qlh250mg | |
Worker: 12
| Comm: tcp://127.0.0.1:36133 | Total threads: 1 |
| Dashboard: /node/gadi-hmem-bdw-0003.gadi.nci.org.au/26997/proxy/39669/status | Memory: 0 B |
| Nanny: tcp://127.0.0.1:44609 | |
| Local directory: /jobfs/130201066.gadi-pbs/dask-scratch-space/worker-mihd4g9d | |
Worker: 13
| Comm: tcp://127.0.0.1:36305 | Total threads: 1 |
| Dashboard: /node/gadi-hmem-bdw-0003.gadi.nci.org.au/26997/proxy/36325/status | Memory: 0 B |
| Nanny: tcp://127.0.0.1:38017 | |
| Local directory: /jobfs/130201066.gadi-pbs/dask-scratch-space/worker-kv0h1773 | |
Worker: 14
| Comm: tcp://127.0.0.1:34417 | Total threads: 1 |
| Dashboard: /node/gadi-hmem-bdw-0003.gadi.nci.org.au/26997/proxy/36091/status | Memory: 0 B |
| Nanny: tcp://127.0.0.1:33607 | |
| Local directory: /jobfs/130201066.gadi-pbs/dask-scratch-space/worker-g3c1re6j | |
Worker: 15
| Comm: tcp://127.0.0.1:40379 | Total threads: 1 |
| Dashboard: /node/gadi-hmem-bdw-0003.gadi.nci.org.au/26997/proxy/33703/status | Memory: 0 B |
| Nanny: tcp://127.0.0.1:39031 | |
| Local directory: /jobfs/130201066.gadi-pbs/dask-scratch-space/worker-wd_v9vm5 | |
Worker: 16
| Comm: tcp://127.0.0.1:33329 | Total threads: 1 |
| Dashboard: /node/gadi-hmem-bdw-0003.gadi.nci.org.au/26997/proxy/34353/status | Memory: 0 B |
| Nanny: tcp://127.0.0.1:43951 | |
| Local directory: /jobfs/130201066.gadi-pbs/dask-scratch-space/worker-6ikw_e4_ | |
Worker: 17
| Comm: tcp://127.0.0.1:38269 | Total threads: 1 |
| Dashboard: /node/gadi-hmem-bdw-0003.gadi.nci.org.au/26997/proxy/42695/status | Memory: 0 B |
| Nanny: tcp://127.0.0.1:35465 | |
| Local directory: /jobfs/130201066.gadi-pbs/dask-scratch-space/worker-3mm7c_ul | |
Worker: 18
| Comm: tcp://127.0.0.1:44209 | Total threads: 1 |
| Dashboard: /node/gadi-hmem-bdw-0003.gadi.nci.org.au/26997/proxy/45005/status | Memory: 0 B |
| Nanny: tcp://127.0.0.1:32925 | |
| Local directory: /jobfs/130201066.gadi-pbs/dask-scratch-space/worker-nj04nxyq | |
Worker: 19
| Comm: tcp://127.0.0.1:39381 | Total threads: 1 |
| Dashboard: /node/gadi-hmem-bdw-0003.gadi.nci.org.au/26997/proxy/41385/status | Memory: 0 B |
| Nanny: tcp://127.0.0.1:37527 | |
| Local directory: /jobfs/130201066.gadi-pbs/dask-scratch-space/worker-iqxway9t | |
Worker: 20
| Comm: tcp://127.0.0.1:34901 | Total threads: 1 |
| Dashboard: /node/gadi-hmem-bdw-0003.gadi.nci.org.au/26997/proxy/46187/status | Memory: 0 B |
| Nanny: tcp://127.0.0.1:43989 | |
| Local directory: /jobfs/130201066.gadi-pbs/dask-scratch-space/worker-osplb9w9 | |
Load in the AUS2200 data¶
Using load_aus2200_variable(). Requires access to the ua8 project on Gadi
[3]:
def load_aus2200_variable(vnames, start_time, end_time, exp_id, lon_slice, lat_slice, freq, hgt_slice=None, chunks="auto"):
'''
Load variables from the mjo-enso AUS2200 experiment, stored on the ua8 project
## Input
* vnames: list of names of aus2200 variables
* start_time: start time in %Y-%m-%d %H:%M"
* end_time: end time in %Y-%m-%d %H:%M"
* exp_id: string describing the experiment. either 'mjo-elnino', 'mjo-lanina' or 'mjo-neutral'
* lat_slice: a slice to restrict lat domain
* lon_slice: a slice to restrict lon domain
* freq: time frequency (string). either "10min", "1hr", "1hrPlev"
* hgt_slice: a slice to restrict data in the vertical (in m)
* chunks: dict describing the number of chunks. see xr.open_dataset
'''
#This code makes sure the inputs for experiment id and time frequency match what is on disk
assert exp_id in ['mjo-elnino', 'mjo-lanina', 'mjo-neutral'], "exp_id must either be 'mjo-elnino', 'mjo-lanina' or 'mjo-neutral'"
assert freq in ["10min", "1hr", "1hrPlev"], "exp_id must either be '10min', '1hr', '1hrPlev'"
#We are loading a list of files from disk using xr.open_mfdataset. This preprocessing
# just slices the lats, lons and levels we are interested in for each file, which is more efficient
def _preprocess(ds):
ds = ds.sel(lat=lat_slice, lon=lon_slice)
return ds
def _preprocess_hgt(ds):
ds = ds.sel(lat=lat_slice, lon=lon_slice, lev=hgt_slice)
return ds
out = []
for vname in vnames:
fnames = "/g/data/ua8/AUS2200/"+exp_id+"/v1-0/"+freq+"/"+vname+"/"+vname+"_AUS2200_"+exp_id+"_*.nc"
if hgt_slice is not None:
ds = xr.open_mfdataset(fnames,
chunks=chunks,
parallel=True,
preprocess=_preprocess_hgt,
engine="h5netcdf").sel(time=slice(start_time, end_time))
else:
ds = xr.open_mfdataset(fnames,
chunks=chunks,
parallel=True,
preprocess=_preprocess,
engine="h5netcdf").sel(time=slice(start_time, end_time))
out.append(ds[vname])
return out
#Define lat lon slices, equivalent to almost the entire AUS2200 domain
lon_slice = slice(108, 159)
lat_slice = slice(-45.7, -6.831799)
#Define times to slice
start_time="2016-01-01 00:00"
end_time="2016-02-01 00:00"
#Load air temperature for a single model level (111.7 m)
aus2200_ta = load_aus2200_variable(["ta"],
start_time,
end_time,
"mjo-elnino",
lon_slice,
lat_slice,
"1hr",
hgt_slice=slice(100, 120),
chunks=({"time":6, "lat":-1, "lon":-1})
)[0]
[4]:
aus2200_ta
[4]:
<xarray.DataArray 'ta' (time: 744, lev: 1, lat: 1963, lon: 2575)> Size: 15GB
dask.array<getitem, shape=(744, 1, 1963, 2575), dtype=float32, chunksize=(6, 1, 1963, 2575), chunktype=numpy.ndarray>
Coordinates:
* time (time) datetime64[ns] 6kB 2016-01-01T01:00:00 ... 2016-02-01
* lev (lev) float64 8B 111.7
* lat (lat) float64 16kB -45.7 -45.68 -45.66 ... -6.891 -6.871 -6.852
* lon (lon) float64 21kB 108.0 108.0 108.1 108.1 ... 158.9 159.0 159.0
Attributes:
standard_name: air_temperature
long_name: Air Temperature
comment: Air Temperature
units: K
cell_methods: area: mean time: point
cell_measures: area: areacella
history: 2023-10-21T14:23:16Z altered by CMOR: replaced mi...
coverage_content_type: modelResultChunks¶
Note that we specified the chunks as {“time”:6,”lat”:-1,”lon”:-1,”lev”:{}}. For lat and lon, “-1” means that the chunk sizes in those dimensions (1963 for lat, 2574 for lon) are equivalent to the length of the dimensions. In other words, the dataset is not chunked up in those dimensions.
However, the dataset is chunked along time (with a chunk size of 6). This is the best we can do for AUS2200 as each file is 6 time steps long. We can rechunk the time dimension later by calling aus2200_ta.chunk({“time”:chunksize}), but this can be very slow.
Our aim is to have small enough chunks to fit on memory, but large enough chunks to reduce the time taken to pass data between workers and to reduce the number of operations dask is doing. The chunk size here (115 MB) is okay, with around 200 MB being a pretty good aim (although there is no standard rules around what chunk sizes are optimal, it takes some experimenting)
Rolling daily mean¶
Now we’d like to compute a rolling daily average temperature. Rolling operations can be very slow, because for each point we need to access neighbouring time chunks
[5]:
time_window = 24 #equivalent to one day for the hourly data here
min_periods = 12 #for each time step, there must be at least 12 hours in the moving window
# for the rolling mean to be defined.
aus2200_ta_daily_mean = aus2200_ta.\
rolling(dim={"time":24},center=True,min_periods=12).\
mean()
[6]:
aus2200_ta_daily_mean
[6]:
<xarray.DataArray 'ta' (time: 744, lev: 1, lat: 1963, lon: 2575)> Size: 15GB
dask.array<truediv, shape=(744, 1, 1963, 2575), dtype=float32, chunksize=(24, 1, 1963, 2575), chunktype=numpy.ndarray>
Coordinates:
* time (time) datetime64[ns] 6kB 2016-01-01T01:00:00 ... 2016-02-01
* lev (lev) float64 8B 111.7
* lat (lat) float64 16kB -45.7 -45.68 -45.66 ... -6.891 -6.871 -6.852
* lon (lon) float64 21kB 108.0 108.0 108.1 108.1 ... 158.9 159.0 159.0
Attributes:
standard_name: air_temperature
long_name: Air Temperature
comment: Air Temperature
units: K
cell_methods: area: mean time: point
cell_measures: area: areacella
history: 2023-10-21T14:23:16Z altered by CMOR: replaced mi...
coverage_content_type: modelResultComputing¶
Note that dask hasn’t done anything yet because we haven’t actually needed to access any data (with only metadata shown above so far). When we start making plots in the following cells, then dask will actually start doing computations and loading the required data into memory.
If for some reason we would like all the data in memory to access it, we can use compute() or perstist() commands, such as
aus2200_ta_daily_mean = aus2200_ta_daily_mean.persist()
Plotting¶
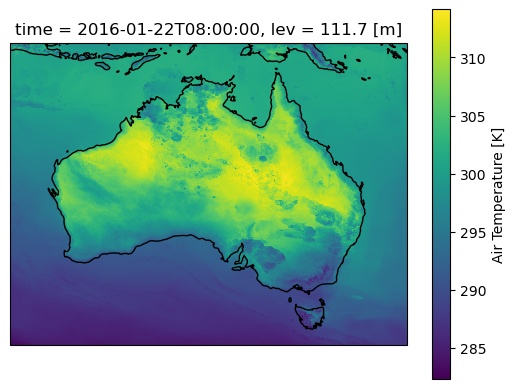
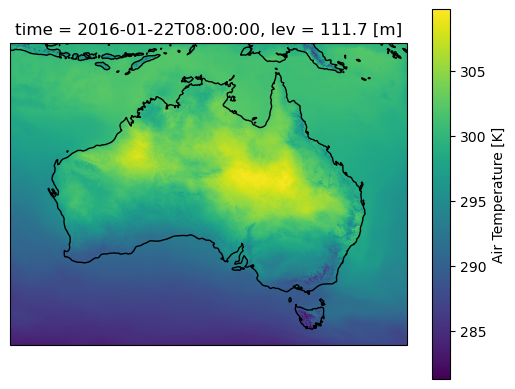
Lets plot a single time step and start some computations. Note that the daily mean here smooths out small variations compared with the original temperature field
[7]:
#First for the original air temperature data
ax=plt.axes(projection=ccrs.PlateCarree())
aus2200_ta.sel(time="2016-01-22 08:00").plot()
ax.coastlines()
[7]:
<cartopy.mpl.feature_artist.FeatureArtist at 0x14a5530aa9e0>
[8]:
#And for the rolling daily mean
ax=plt.axes(projection=ccrs.PlateCarree())
aus2200_ta_daily_mean.sel(time="2016-01-22 08:00").plot()
ax.coastlines()
[8]:
<cartopy.mpl.feature_artist.FeatureArtist at 0x14a552fac190>
Perturbations¶
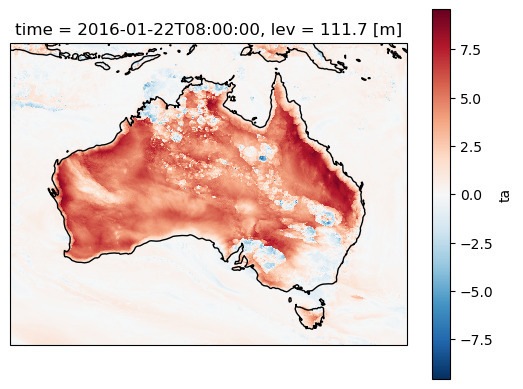
Now calculate the temperature perturbations relative to the daily mean. Perturbations will re-introduce and highlight small-scale factors like convective cold pools and sea breezes along the coast, as well as allowing us to quantify the diurnal cycle.
[9]:
aus2200_ta_daily_pert = aus2200_ta - aus2200_ta_daily_mean
[10]:
aus2200_ta_daily_pert
[10]:
<xarray.DataArray 'ta' (time: 744, lev: 1, lat: 1963, lon: 2575)> Size: 15GB dask.array<sub, shape=(744, 1, 1963, 2575), dtype=float32, chunksize=(6, 1, 1963, 2575), chunktype=numpy.ndarray> Coordinates: * time (time) datetime64[ns] 6kB 2016-01-01T01:00:00 ... 2016-02-01 * lev (lev) float64 8B 111.7 * lat (lat) float64 16kB -45.7 -45.68 -45.66 ... -6.891 -6.871 -6.852 * lon (lon) float64 21kB 108.0 108.0 108.1 108.1 ... 158.9 159.0 159.0
Plotting¶
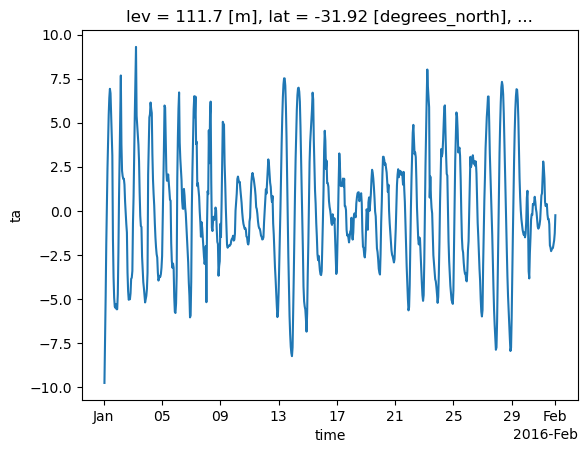
As above, but for temperatue perturbations. Also plot for a single lat/lon location for the entire month
Note that the time series computation takes a lot longer, because dask needs to access many more files on disk (AUS2200 data is saved in 6-hourly files as discussed earlier)
[11]:
ax=plt.axes(projection=ccrs.PlateCarree())
aus2200_ta_daily_pert.sel(time="2016-01-22 08:00").plot()
ax.coastlines()
[11]:
<cartopy.mpl.feature_artist.FeatureArtist at 0x14a553003a90>
[12]:
aus2200_ta_daily_pert.sel(lat=-31.9275, lon=115.9764, method="nearest").plot()
[12]:
[<matplotlib.lines.Line2D at 0x14a552e95660>]
Contributors¶
Andrew Brown
ARC Centre of Excellence for 21st Century Weather, University of Melbourne
Samuel Green
ARC Centre of Excellence for 21st Century Weather & Climate Change Research Centre, UNSW Sydney
If you have any enquries, suggested improvements or bug reports related to this recipe, please open an issue or start a discussion in this repository.