Demo for the AUS2200 intake catalogue¶
How to load output for an experiment without knowledge where the output lives on NCI¶
[1]:
import intake
import cf_xarray
[2]:
catalog = intake.cat.access_nri['AUS2200']
# Until https://github.com/ACCESS-NRI/access-nri-intake-catalog/pull/621 is merged
catalog = catalog.unwrap()
You can also explore datasets in the intake catalog via https://access-nri.github.io/interactive-data-catalogue/#/, which will give you an interactive way to explore them in a browser¶
List all the datasets available.
[3]:
list(catalog)[:5]
[3]:
['f.AUS2200.6hrPlev.zg.v1-0',
'f.AUS2200.1hr.pfull.v1-0',
'f.AUS2200.1hr.rsdsdiff.v1-0',
'f.AUS2200.1hr.hus.v1-0',
'f.AUS2200.1hr.va.v1-0']
[4]:
# This is not very helpful - so lets figure out what is in the datastore
catalog
AUS2200 catalog with 61 dataset(s) from 21471 asset(s):
| unique | |
|---|---|
| path | 21471 |
| file_type | 1 |
| realm | 2 |
| model_id | 1 |
| experiment_id | 16 |
| frequency | 6 |
| variable_id | 48 |
| version | 1 |
| time_range | 2054 |
| derived_variable_id | 0 |
[5]:
# experiment_id looks like it might be helpful!
catalog.unique().experiment_id
[5]:
['mjo-lanina2018',
'mjo-elnino2016',
'coralsea-sstreduced',
'ashwed1983',
'mjo-neutral2013',
'canberra2003',
'flood2022',
'ashwed1980',
'ecoastlow-corclimsst',
'blacksat2009',
'ecoastlow-smooth',
'ecoastlow-evolvsst',
'ecoastlow-climsst',
'ecoastlow-tasclimsst',
'coralsea-sstobs',
'ecoastlow-fixsst']
[6]:
# Lets pick the Canberra 2003 experiment
experiment = catalog.search(experiment_id='canberra2003')
At the moment we have one dataset for each separate simulation and a combined dataset which includes all simulations.
Example of dataset for a single simulation: canberra03¶
[7]:
# Lets pick the Canberra 2003 experiment
experiment = catalog.search(experiment_id='canberra2003')
experiment
AUS2200 catalog with 56 dataset(s) from 341 asset(s):
| unique | |
|---|---|
| path | 341 |
| file_type | 1 |
| realm | 2 |
| model_id | 1 |
| experiment_id | 1 |
| frequency | 4 |
| variable_id | 47 |
| version | 1 |
| time_range | 35 |
| derived_variable_id | 0 |
What are the available variables?
[8]:
experiment.unique()['variable_id']
[8]:
['rainmxrat',
'vas',
'refl',
'cl',
'wa',
'clmed',
'clw',
'ta',
'cli',
'grplmxrat',
'hus',
'pralsns',
'eow',
'theta',
'tke',
'uas',
'hfss',
'va',
'pralsprof',
'hfls',
'ua',
'pfull',
'huss',
'clmxro',
'rsds',
'mrsol',
'psl',
'rsdt',
'reflmax',
'estot',
'wsgmax10m',
'evspsbl',
'lmask',
'z0',
'clhigh',
'cllow',
'rsut',
'rss',
'rsdsdir',
'orog',
'mrso',
'tas',
'zmla',
'rlds',
'rls',
'rsdsdiff',
'rlut']
Let’s get one (e.g., the temperature) and do some super-duper analysis!
[9]:
ds = experiment.search(variable_id='tas', frequency="1hr").to_dask()
ds
[9]:
<xarray.Dataset> Size: 2GB
Dimensions: (time: 96, bnds: 2, lat: 2120, lon: 2600)
Coordinates:
* time (time) datetime64[ns] 768B 2003-01-16T00:29:59.999999872 ... 2...
* lat (lat) float64 17kB -48.79 -48.77 -48.75 ... -6.871 -6.852 -6.832
* lon (lon) float64 21kB 107.5 107.5 107.6 107.6 ... 158.9 159.0 159.0
height float64 8B ...
Dimensions without coordinates: bnds
Data variables:
time_bnds (time, bnds) datetime64[ns] 2kB dask.array<chunksize=(96, 2), meta=np.ndarray>
lat_bnds (lat, bnds) float64 34kB dask.array<chunksize=(2120, 2), meta=np.ndarray>
lon_bnds (lon, bnds) float64 42kB dask.array<chunksize=(2600, 2), meta=np.ndarray>
tas (time, lat, lon) float32 2GB dask.array<chunksize=(6, 2120, 2600), meta=np.ndarray>
Attributes: (12/57)
Conventions: CF-1.7 ACDD1.3
creation_date: 2023-10-19T06:04:51Z
data_specs_version: 01.00.00
date_created: 2023-06-05
exp_description: A limited area model study of the entire...
external_variables: areacella
... ...
intake_esm_attrs:frequency: 1hr
intake_esm_attrs:variable_id: tas
intake_esm_attrs:version: v1-0
intake_esm_attrs:time_range: 200301160030-200301192330
intake_esm_attrs:_data_format_: netcdf
intake_esm_dataset_key: f.AUS2200.1hr.tas.v1-0[10]:
tas = ds['tas']
tas
[10]:
<xarray.DataArray 'tas' (time: 96, lat: 2120, lon: 2600)> Size: 2GB
dask.array<open_dataset-tas, shape=(96, 2120, 2600), dtype=float32, chunksize=(6, 2120, 2600), chunktype=numpy.ndarray>
Coordinates:
* time (time) datetime64[ns] 768B 2003-01-16T00:29:59.999999872 ... 200...
* lat (lat) float64 17kB -48.79 -48.77 -48.75 ... -6.871 -6.852 -6.832
* lon (lon) float64 21kB 107.5 107.5 107.6 107.6 ... 158.9 159.0 159.0
height float64 8B ...
Attributes:
standard_name: air_temperature
long_name: Near-Surface Air Temperature
comment: near-surface (for access 1.5 meters) air temperature
units: K
cell_methods: area: mean time: mean
cell_measures: area: areacella
history: 2023-10-19T06:04:25Z altered by CMOR: Treated sca...
coverage_content_type: modelResult[11]:
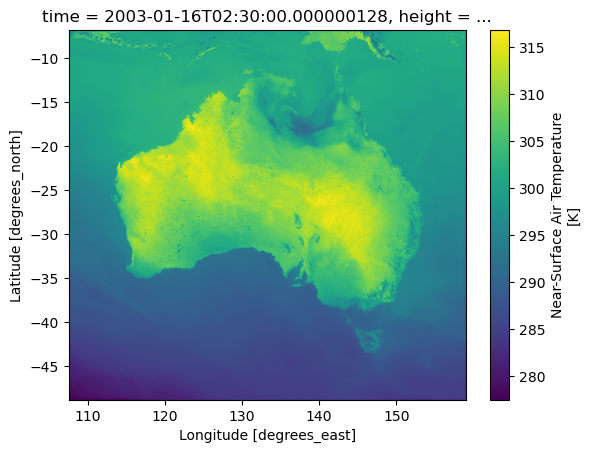
tas.cf.sel(time = '2003-01-16T02:30:00').plot()
[11]:
<matplotlib.collections.QuadMesh at 0x15278ab032c0>
Plot a Hovmoller
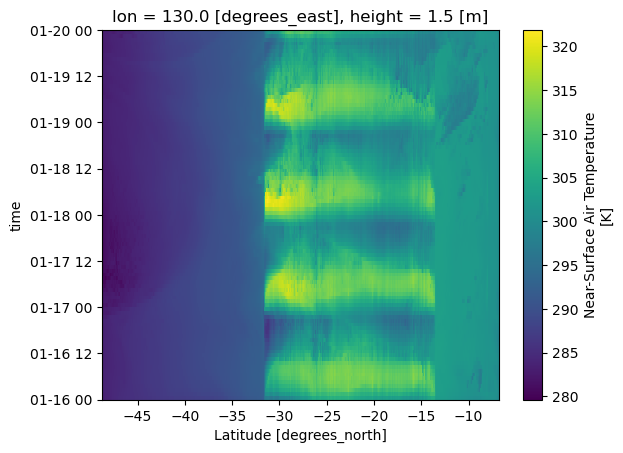
[12]:
tas.cf.sel(longitude = 130, method='nearest').plot()
[12]:
<matplotlib.collections.QuadMesh at 0x15271aea5310>